
Note
Go to the end to download the full example code.
Growth of diamond film using CVD#
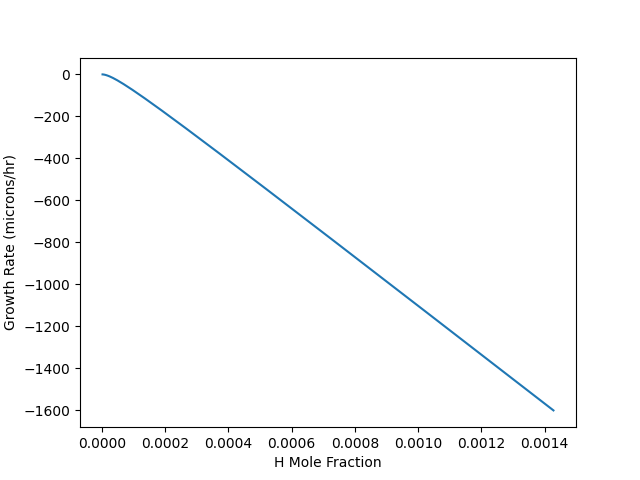
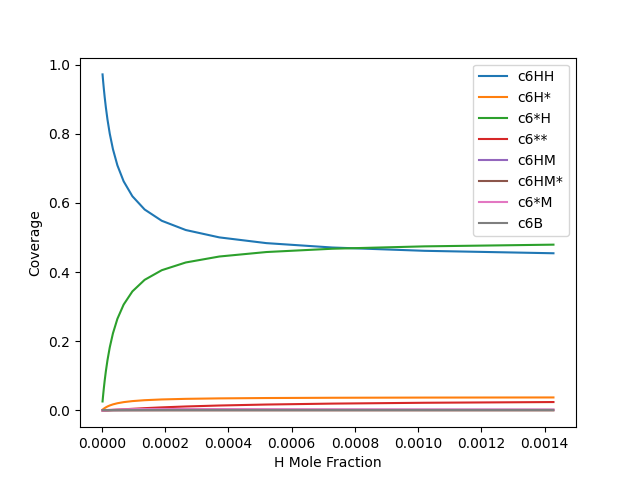
This example computes the growth rate of a diamond film according to a simplified version of a particular published growth mechanism (see diamond.yaml for details). Only the surface coverage equations are solved here; the gas composition is fixed. (For an example of coupled gas-phase and surface, see catalytic_combustion.py.) Atomic hydrogen plays an important role in diamond CVD, and this example computes the growth rate and surface coverages as a function of [H] at the surface for fixed temperature and [CH3].
Requires: cantera >= 2.6.0, pandas >= 0.25.0, matplotlib >= 2.0
import csv
import matplotlib.pyplot as plt
import pandas as pd
import cantera as ct
Import the model for the diamond (100) surface and the adjacent bulk phases
d = ct.Interface("diamond.yaml", "diamond_100")
g = d.adjacent["gas"]
dbulk = d.adjacent["diamond"]
mw = dbulk.molecular_weights[0]
t = 1200.0
x = g.X
p = 20.0 * ct.one_atm / 760.0 # 20 Torr
g.TP = t, p
ih = g.species_index('H')
xh0 = x[ih]
Calculate growth rate as a function of H mole fraction in the gas
with open('diamond.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(['H mole Fraction', 'Growth Rate (microns/hour)'] +
d.species_names)
iC = d.kinetics_species_index('C(d)')
for n in range(20):
x[ih] /= 1.4
g.TPX = t, p, x
d.TP = t, p
d.advance_coverages_to_steady_state()
carbon_dot = d.net_production_rates[iC]
mdot = mw * carbon_dot
rate = mdot / dbulk.density
writer.writerow([x[ih], rate * 1.0e6 * 3600.0] + list(d.coverages))
print('H concentration, growth rate, and surface coverages '
'written to file diamond.csv')
H concentration, growth rate, and surface coverages written to file diamond.csv
Plot the results
data = pd.read_csv('diamond.csv')
data.plot(x="H mole Fraction", y="Growth Rate (microns/hour)", legend=False)
plt.xlabel('H Mole Fraction')
plt.ylabel('Growth Rate (microns/hr)')
plt.show()
names = [name for name in data.columns if not name.startswith(('H mole', 'Growth'))]
data.plot(x='H mole Fraction', y=names, legend=True)
plt.xlabel('H Mole Fraction')
plt.ylabel('Coverage')
plt.show()
Total running time of the script: (0 minutes 0.361 seconds)